After nearly 11 years I've finally built my own blog and am leaving this blog and Blogger behind.
The new blog is at www.kevinberridge.com, and I wrote about the switch in the first post on the new blog.
It's been fun Blogger, thanks for everything.
Friday, January 26, 2018
Wednesday, February 3, 2016
HG: What Changesets Are Not In This Tag?
I still love Mercurial. You git people can pry it from my cold dead hands!
Mercurial has a search feature called revsets (hg help revsets) which is a simple and powerful query language for searching the changeset history graph. I probably don't use it as often as I should, instead wasting time scrolling through the thg graph hunting for things or following branch lines. But I did use it today and thought I'd share.
We have a release branch and we tag changesets with version numbers when we release. We're in a rather unusual period of chaos at the moment which had led to changesets on the release branch that had not been included in the last tagged release because the release was done from an anonymous head. As a result, it was hard to know exactly what changesets were not included in that tag. Enter revsets:
hg sl -r "sort(branch(release) and not ancestors(tag-name) and not merge(), -rev)"
This gets all changesets on the release branch which are not an ancestor of the given tag (AKA were not included in the release represented by that tag) and are not a merge changeset sorted by revision number descending.
Mercurial has a search feature called revsets (hg help revsets) which is a simple and powerful query language for searching the changeset history graph. I probably don't use it as often as I should, instead wasting time scrolling through the thg graph hunting for things or following branch lines. But I did use it today and thought I'd share.
We have a release branch and we tag changesets with version numbers when we release. We're in a rather unusual period of chaos at the moment which had led to changesets on the release branch that had not been included in the last tagged release because the release was done from an anonymous head. As a result, it was hard to know exactly what changesets were not included in that tag. Enter revsets:
hg sl -r "sort(branch(release) and not ancestors(tag-name) and not merge(), -rev)"
This gets all changesets on the release branch which are not an ancestor of the given tag (AKA were not included in the release represented by that tag) and are not a merge changeset sorted by revision number descending.
Monday, January 26, 2015
Why We Write Tests
Software Testing is ubiquitous these days. It seems that every software development book has at least one section about testing. Every conference seems to have a testing track. And for what it's worth most of the developers I know are writing tests too. Not all of them, sadly, but most of them!
But even with all this activity and talking around testing, I still find myself troubled by whether I'm using them "right." As simple as testing seems at first glance, it’s a big subject. There are all these contentious arguments about how it should be done. From what kinds of tests we should write, to when we should write them, to exactly how they should be written. It's easy to be overwhelmed by these details and lose sight of what is important, causing bad decisions to be made, or time to be wasted on issues that might not be so important in the big scheme of things.
A clear understanding of the motivations of a technique, like testing, can keep the focus on what matters and can guide a good application of the technique to a specific scenario. And this can shed some light on why other people's opinions and practice might differ due to their different context.
In the case of testing, I think we can summarize the motivations of the technique by asking a very simple question: why do we write tests?
OK great! So why do developers write tests?
Because. Because people say we should. And for a lot of people, I think “because” is the only reason they’ve ever been given. But there are reasons, and chief among them is this:
The next reason is really simple. Automated tests can save you a lot of time and be more effective than manual tests alone. They don't replace manual tests, but automated tests can take some of the regression testing burden off of the manual testers, saving the whole team time. Plus automated tests can be run faster and more often, providing feedback more quickly. And you can also write automated tests for things that may be impossible to test manually, like error conditions, helping you find bugs earlier.
Tests can also serve as documentation of code, helping us to understand existing code faster and to work with it more effectively. And along these same lines, tests can be used like an experiment to prove how some code actually works, saving on time spent mentally reasoning about how it should work and cutting straight to the chase.
Another big and commonly cited reason is that writing tests helps cut down on the amount of time we spend debugging. Debugging is awful. Once you have to fire up a debugger there is absolutely no way to know how long you'll be at it. But people who write tests have experienced how much less time needs to be spent in the debugger. And the time that does need to be spent seems lessened partly because tests localize the area of code that might have the problem.
All of these are ways that writing and having tests helps lower the costs of development. But probably the most important way tests help lower the cost of development is this: confidence. You might think we're talking about confidence in the correctness or quality of code, and that's part of it, but it's not the biggest part. The biggest part is actually that we have confidence to change the code! Why would this be so important?
Refactoring code is important, and yes, I know that this is not earth shattering news. But I feel like we often think of refactoring as this thing we do later. Like, once things get bad enough, we can always come back and refactor. But that's not right. That kind of thinking just makes software rot faster!
When we have big changes to make, the need to refactor is obvious. But it's when the changes we're making are small that we really get into trouble! The small changes are the ones that we shoe horn into the code. "I'll just add an if statement here" we think, "It makes it work, what's the harm?"
What's the harm? Software rot! That is software rot happening right before your eyes. Those seemingly small changes have a tendency to compound, rendering the code unintelligible. And in addition, surprisingly often, the small changes represent a major shift in the appropriate design. But even if we are aware of this, we ignore it. Why?
We ignore it because we're trying to get the feature done so we can move on to the next thing. We're trying to be productive! Little realizing we are shooting ourselves in the foot. But we also ignore it because we think it's safer to change the code as little as possible. We have learned to avoid making "invasive" changes to code because we've seen even the simplest of changes break stuff. We've internalized this fear of change. And that's why we shoe horn in changes, but of course this inevitably leads to software rot!
And rotten code just makes us more afraid, which leads us to shoe horn in more changes, leading to even more rotten code, and around and around we go!
Which finally brings us back to confidence. What we need to break out of this destructive loop is the confidence to make those "invasive" code and design changes. Because if we don't have that confidence we wont make the kind of code changes that we absolutely need to make to prevent our code from rotting!
When we have tests, we know we can change code. Because if something goes wrong, the tests will tell us right away. We can refactor constantly, working to keep the code as simple and communicative as possible at all times. If something goes wrong, the tests will tell us right away. We can shoe horn in changes, but then we can take that next critical step of refactoring the design to reflect it's new requirements! If something goes wrong, the tests will tell us right away. We can experiment with new names or new class structures and see what works best. If something goes wrong, the tests will tell us right away. We can truly live the Boy Scout rule, leaving code cleaner than it was when we found it. And if something goes wrong, the tests will tell us right away.
And all of this will mean that our code is as intention revealing and simple as possible. And in a code base like that, we can quickly respond to new feature requests and surprising bugs. We can take on enhancements and incorporate new ideas that with a rotted code base we would probably have had to say no to. And that means not only are we delivering features and enhancements faster, we're building a better product too! This is the promise of tests, and it's the ultimate motivation for why developers write tests.
1. Practical Object-Oriented Design in Ruby
But even with all this activity and talking around testing, I still find myself troubled by whether I'm using them "right." As simple as testing seems at first glance, it’s a big subject. There are all these contentious arguments about how it should be done. From what kinds of tests we should write, to when we should write them, to exactly how they should be written. It's easy to be overwhelmed by these details and lose sight of what is important, causing bad decisions to be made, or time to be wasted on issues that might not be so important in the big scheme of things.
A clear understanding of the motivations of a technique, like testing, can keep the focus on what matters and can guide a good application of the technique to a specific scenario. And this can shed some light on why other people's opinions and practice might differ due to their different context.
In the case of testing, I think we can summarize the motivations of the technique by asking a very simple question: why do we write tests?
Why do we write tests?
To start with, I should be very clear that I'm talking about developers here. I am not talking about why a separate QA department might write tests. If you work in an environment with a separate test-writing QA department, it may change some of the algebra of how you approach testing, and certainly the QA people themselves will have very different motivations from the developers. But none of that will change the major motivations and benefits for why developers write tests. Which serves as a great example of why understanding the underpinning motivations is so important!OK great! So why do developers write tests?
Because. Because people say we should. And for a lot of people, I think “because” is the only reason they’ve ever been given. But there are reasons, and chief among them is this:
Testing, done well, makes software development take less time, thereby reducing the costs of development. But this is really surprising, isn't it? How could adding the work of testing possibly make development take less time? Especially given that the #1 excuse I hear for why people don't test is because they think they don't have time for it! Which does make sense, after all writing tests necessarily means writing more code. By some estimates up to 2 lines of test code for every 1 line of production code! That is a lot more code! And even given the fact that lines of code is a horrible metric, that still represents a significant amount of extra work."The true purpose of testing, just like the true purpose of design, is to reduce costs."1
How could testing reduce development cost?
There are, in fact, a lot of productivity benefits that developers derive from having and writing tests. I want to just quickly summarize a few of them before we get to the really big one. The first is this: "Fixing bugs early always lowers costs."1 When a developer is "in the zone" with some code, it takes significantly less time to track down and fix issues. So if tests can help us find issues when we're in the zone, that's a great time savings. And, of course, finding a bug before it gets into production is a HUGE time savings to the organization as a whole.The next reason is really simple. Automated tests can save you a lot of time and be more effective than manual tests alone. They don't replace manual tests, but automated tests can take some of the regression testing burden off of the manual testers, saving the whole team time. Plus automated tests can be run faster and more often, providing feedback more quickly. And you can also write automated tests for things that may be impossible to test manually, like error conditions, helping you find bugs earlier.
Tests can also serve as documentation of code, helping us to understand existing code faster and to work with it more effectively. And along these same lines, tests can be used like an experiment to prove how some code actually works, saving on time spent mentally reasoning about how it should work and cutting straight to the chase.
Another big and commonly cited reason is that writing tests helps cut down on the amount of time we spend debugging. Debugging is awful. Once you have to fire up a debugger there is absolutely no way to know how long you'll be at it. But people who write tests have experienced how much less time needs to be spent in the debugger. And the time that does need to be spent seems lessened partly because tests localize the area of code that might have the problem.
All of these are ways that writing and having tests helps lower the costs of development. But probably the most important way tests help lower the cost of development is this: confidence. You might think we're talking about confidence in the correctness or quality of code, and that's part of it, but it's not the biggest part. The biggest part is actually that we have confidence to change the code! Why would this be so important?
Software rot
Software rot is the phenomenon where by code gets worse as time goes on. If you've worked for any kind of duration on a project you've doubtless experienced it. But why does our software rot like this? The simple answer is because we so often fail to refactor.Refactoring code is important, and yes, I know that this is not earth shattering news. But I feel like we often think of refactoring as this thing we do later. Like, once things get bad enough, we can always come back and refactor. But that's not right. That kind of thinking just makes software rot faster!
When we have big changes to make, the need to refactor is obvious. But it's when the changes we're making are small that we really get into trouble! The small changes are the ones that we shoe horn into the code. "I'll just add an if statement here" we think, "It makes it work, what's the harm?"
What's the harm? Software rot! That is software rot happening right before your eyes. Those seemingly small changes have a tendency to compound, rendering the code unintelligible. And in addition, surprisingly often, the small changes represent a major shift in the appropriate design. But even if we are aware of this, we ignore it. Why?
We ignore it because we're trying to get the feature done so we can move on to the next thing. We're trying to be productive! Little realizing we are shooting ourselves in the foot. But we also ignore it because we think it's safer to change the code as little as possible. We have learned to avoid making "invasive" changes to code because we've seen even the simplest of changes break stuff. We've internalized this fear of change. And that's why we shoe horn in changes, but of course this inevitably leads to software rot!
And rotten code just makes us more afraid, which leads us to shoe horn in more changes, leading to even more rotten code, and around and around we go!
Which finally brings us back to confidence. What we need to break out of this destructive loop is the confidence to make those "invasive" code and design changes. Because if we don't have that confidence we wont make the kind of code changes that we absolutely need to make to prevent our code from rotting!
So, why do we write tests?
Because tests are the best and cheapest tool that we have to manage fear and replace it with confidence, so that we can and will refactor, so that our code doesn't rot, so that we can build software faster, indefinitely.When we have tests, we know we can change code. Because if something goes wrong, the tests will tell us right away. We can refactor constantly, working to keep the code as simple and communicative as possible at all times. If something goes wrong, the tests will tell us right away. We can shoe horn in changes, but then we can take that next critical step of refactoring the design to reflect it's new requirements! If something goes wrong, the tests will tell us right away. We can experiment with new names or new class structures and see what works best. If something goes wrong, the tests will tell us right away. We can truly live the Boy Scout rule, leaving code cleaner than it was when we found it. And if something goes wrong, the tests will tell us right away.
And all of this will mean that our code is as intention revealing and simple as possible. And in a code base like that, we can quickly respond to new feature requests and surprising bugs. We can take on enhancements and incorporate new ideas that with a rotted code base we would probably have had to say no to. And that means not only are we delivering features and enhancements faster, we're building a better product too! This is the promise of tests, and it's the ultimate motivation for why developers write tests.
1. Practical Object-Oriented Design in Ruby
Wednesday, October 1, 2014
Coming Soon To CodeMash: The Cartography of Testing
Last year I had the amazing experience of giving my OOP: You're Doing It Completely Wrong talk to a standing room only crowd at CodeMash (and later at Stir Trek). It was a crazy experience standing at the side of the room and watching people come in, my reaction going from, "oh this is a good crowd" to "wow, this a big crowd" to "holy crap!!!".
The idea for the OOP talk came from a question I found myself asking a lot, which was basically, "I know what objects are, but am I using them right"? Then I went and did a bunch of research and tried to coalesce all that into a coherent presentation of OO. So when I set out to think of a talk for this year I found myself starting in a similar place, but this time thinking about testing. The question is basically, "I know what tests are, but am I using them right?" Testing is such a big and contentious subject that I was pretty nervous to tackle it, but I like the idea that you should give the talk you wish you could attend. So I wrote it up, and CodeMash accepted it, and here's the abstract for my talk at CodeMash this year!
Imagine diagramming your application like a map. The methods might be like cities and the classes like states. The more coupled two methods or classes are, the closer their cities or states may be to each other. Let's spread this map out before us and ask, "how do we best deploy our tests across this landscape"? There are many different kinds of test (unit, acceptance, etc.), each serving a different purpose. What mix of these will best cover the terrain? Well positioned tests can give us confidence in our code, document business rules, support refactoring, and make building new features easier. But poorly positioned tests can just as easily undermine all these goals. How do you find the right balance and test deployment strategy for your application's landscape? In this talk, we will look at the trade-offs in the different kinds of tests and survey recommendations for deploying them effectively.
Hope to you see at the Kalahari in January!
Friday, August 22, 2014
Unit Testing Question
Hi there. I have a question for you. I'm looking for some articles/papers/blogs/talks about Unit Testing at the right level of granularity. Could you send me some links?
Let me try to explain what I mean. I've noticed that when you write what I'll call "good OO" (for the sake of simplicity) you tend to end up with individual objects which on their own don't do that much. Instead the behavior that you care about emerges from the way in which the objects are composed together. And this poses an interesting problem for unit testing.
If I define a unit as a single object, then I will write tests for each of those little objects and I'll mock/stub/fake out the collaborators. But since each object doesn't do much this means my tests do not end up describing the behavior of the system that I'm usually concerned with. These tests might also get in my way during new development or refactoring because the "low level" individual APIs are locked in by the tests.
Alternatively, I could write tests that exercise the full composition of all the objects. These tests would be closer to describing the "end user" level behavior that I more likely care about. They are also more robust in the face of change as the lower level API can change without breaking these tests. But, they can also suffer from Cyclomatic complexity problems because they are testing many levels of objects together.
These last tests can be taken all the way to the edge of the application and written as Acceptance Tests that literally automate the web browser. Or they can be written like a regular unit test, but the "unit" is at a higher conceptual level, not just a single object.
Finally, these are not mutually exclusive options. I could write both kinds of tests.
So to loop back, my question for YOU is, have you seen any good resources that discuss this issue and make any recommendations? If so, I'd love a link, or, share your opinions on the issue. Thanks!
Let me try to explain what I mean. I've noticed that when you write what I'll call "good OO" (for the sake of simplicity) you tend to end up with individual objects which on their own don't do that much. Instead the behavior that you care about emerges from the way in which the objects are composed together. And this poses an interesting problem for unit testing.
If I define a unit as a single object, then I will write tests for each of those little objects and I'll mock/stub/fake out the collaborators. But since each object doesn't do much this means my tests do not end up describing the behavior of the system that I'm usually concerned with. These tests might also get in my way during new development or refactoring because the "low level" individual APIs are locked in by the tests.
Alternatively, I could write tests that exercise the full composition of all the objects. These tests would be closer to describing the "end user" level behavior that I more likely care about. They are also more robust in the face of change as the lower level API can change without breaking these tests. But, they can also suffer from Cyclomatic complexity problems because they are testing many levels of objects together.
These last tests can be taken all the way to the edge of the application and written as Acceptance Tests that literally automate the web browser. Or they can be written like a regular unit test, but the "unit" is at a higher conceptual level, not just a single object.
Finally, these are not mutually exclusive options. I could write both kinds of tests.
So to loop back, my question for YOU is, have you seen any good resources that discuss this issue and make any recommendations? If so, I'd love a link, or, share your opinions on the issue. Thanks!
Wednesday, May 21, 2014
Close old hg branches with powershell
Another silly post combining my two favorite tools: Mercurial and Powershell.
If you use named branches as part of your development workflow you may occasionally forget to close a branch after you merge it back in. Or you might abandon a branch and never get back to it. And if you use sub repositories, sometimes it can be impossible to update back to those old revisions... And even if you don't get an error when you update back, it's still super slow to checkout all those old files just to mark the branch closed.
To address all those issues, I just used this little powershell script:
If you use named branches as part of your development workflow you may occasionally forget to close a branch after you merge it back in. Or you might abandon a branch and never get back to it. And if you use sub repositories, sometimes it can be impossible to update back to those old revisions... And even if you don't get an error when you update back, it's still super slow to checkout all those old files just to mark the branch closed.
To address all those issues, I just used this little powershell script:
function closeoldbranch($branchname)
{
hg debugsetparent $branchname
hg branch $branchname
hg ci --close-branch -m "closes old branch"
}
I don't recommend that you make a habit of using this technique, but I did just get a lot of use out of it! So enjoy it, but be careful!
Thursday, April 10, 2014
OOP: You're Doing It Completely Wrong
OOP: You're Doing It Completely Wrong (Stir Trek Edition)
This talk, "OOP: You're Doing It Completely Wrong", was first presented at CodeMash 2.0.1.4. in January to a standing room only crowd. It was the 2nd time I was fortunate enough to present at CodeMash and it was an absolute blast! The feedback I got was really encouraging and someone suggested I should submit it to other conferences and recommended Stir Trek. The video above is the recording of the talk as it was given at Stir Trek 2014 in April (to another standing room only crowd!).
Here's the abstract:
Chances are, most of us are primarily writing in Object Oriented Languages. But how many of us are truly doing Object Oriented Programming (OOP)? Objects are a powerful abstraction, but when all we do is write procedural code wrapped in classes we’re not realizing their benefits. That’s the tricky thing about OO, it’s easy to have Objects but still not be doing good OOP. This has led to a plethora of principles and patterns and laws, which are very valuable, but also easy to misunderstand and misapply. In this talk we’ll go back to the foundations of Objects, and take a careful look at what OO is really about and how our principles and patterns fit into the big picture. We’ll see why good OOP is important, and look at the mindset needed to design successful Objects. When we’re done, we’ll have a more nuanced understanding of what good OO is, what it can do for us, and when we should use it.Between CodeMash and Stir Trek I had the time to really work through and reorganize the details of the talk, so I actually COMPLETELY rewrote it from the ground up for Stir Trek. And I will admit that I'm really proud of the result.
This talk truly represents my (current) understanding of what makes OO powerful and how we should really think about it. It's VERY heavy on research and full of quotes and references. The CodeMash version was even more so. And that reflects my belief that we, as an industry, need to work on being a bit more scientific, especially when it comes to citing our references.
I hope that you enjoy it, and I'd love to hear your thoughts!
Sunday, April 6, 2014
Visual Studio Shortcuts: The Complete Guide
So I was gonna do this whole series of posts breaking out useful shortcuts into categories in bite sized chunks. But that didn't happen cause I got bored with it. But I still think it's really useful. I have actually stopped using VSVIM and I just use VS's shortcuts now. The only thing I really miss is vim's hjkl and w and b movement keys (the arrow keys are so far away!).
So, anyway, here's the big list of all the shortcut keys I have found useful and worth practicing. Each category is roughly sorted by utility. Hope it helps you too!
Editing:
Ctrl+L: cuts the current line
Ctrl+del: Join lines
Shift+del: delete line
Ctrl+C with nothing selected: copies current line
Ctrl+F3: search for current select (like VIM *)
Ctrl+Enter; Ctrl+Shift+Enter: insert blank line above/below current line
Ctrl+Shift+W: select word (like VIM viw)
Ctrl+K, S: surround with
Ctrl+E, S: show white space
Ctrl+U: to lower case
Ctrl+Shift+U: to upper case
Ctrl+Shift+down/up: move cursor to next highlighted identifier
Ctrl+Shift+V: cycle clipboard ring
Ctrl+up/down: moves the scrollbar
Intellisense: use capital case to filter by camel case
Refactoring:
Ctrl+R, R: rename
Ctrl+R, M: extract method
Windows:
Ctrl+,: navigate to window
Ctrl+W, L: opens solution explorer
Ctrl+F2: move to navigation bar (the class and method dropdowns)
CUSTOM: Ctrl+W, ctrl+left/right arrow: move window to other tab group **Window.MovetoNextTabGroup/Window.MovetoPreviousTabGroup**
CUSTOM: Ctrl+W, Ctrl+W: switch focus to other tab group **TabGroupJumper.Connect.JumpLeft, requires TabGroupJumper extension**
Ctrl+W, E: opens error window
Ctrl+K, T: opens call hierarchy window (like Find all References, but more)
Ctrl+W, O: opens output window
Debugging:
Ctrl+D, A: opens autos window
Ctrl+D, I: opens immediate window
Ctrl+D, C: opens callstack window
Misc:
Snippet designer extension: makes it really easy to create snippets
zencoding: comes with the Web Essentials extension, allows you to quickly expand HTML tag structure ex: div.content
So, anyway, here's the big list of all the shortcut keys I have found useful and worth practicing. Each category is roughly sorted by utility. Hope it helps you too!
Editing:
Ctrl+L: cuts the current line
Ctrl+del: Join lines
Shift+del: delete line
Ctrl+C with nothing selected: copies current line
Ctrl+F3: search for current select (like VIM *)
Ctrl+Enter; Ctrl+Shift+Enter: insert blank line above/below current line
Ctrl+Shift+W: select word (like VIM viw)
Ctrl+K, S: surround with
Ctrl+E, S: show white space
Ctrl+U: to lower case
Ctrl+Shift+U: to upper case
Ctrl+Shift+down/up: move cursor to next highlighted identifier
Ctrl+Shift+V: cycle clipboard ring
Ctrl+up/down: moves the scrollbar
Intellisense: use capital case to filter by camel case
Refactoring:
Ctrl+R, R: rename
Ctrl+R, M: extract method
Windows:
Ctrl+,: navigate to window
Ctrl+W, L: opens solution explorer
Ctrl+F2: move to navigation bar (the class and method dropdowns)
CUSTOM: Ctrl+W, ctrl+left/right arrow: move window to other tab group **Window.MovetoNextTabGroup/Window.MovetoPreviousTabGroup**
CUSTOM: Ctrl+W, Ctrl+W: switch focus to other tab group **TabGroupJumper.Connect.JumpLeft, requires TabGroupJumper extension**
Ctrl+W, E: opens error window
Ctrl+K, T: opens call hierarchy window (like Find all References, but more)
Ctrl+W, O: opens output window
Debugging:
Ctrl+D, A: opens autos window
Ctrl+D, I: opens immediate window
Ctrl+D, C: opens callstack window
Misc:
Snippet designer extension: makes it really easy to create snippets
zencoding: comes with the Web Essentials extension, allows you to quickly expand HTML tag structure ex: div.content
Friday, October 18, 2013
ETB: Editing: Just 3 Shortcuts for Dramatic Efficiency Gain
Continuing on the Embracing The Beast (ETB) series, this time we're going to dive into the text editor.
If you edit at all like I used to, these 3 shortcut keys will save you a huge number of redundant keystrokes every single day. Yep, just learning 3 new shortcut keys.
I'm not going to keep you waiting, here they are:
I have learned tons of new shortcut keys since I started this process, but these three are the most important. If you learn this and nothing else in this series, it will still be a marked improvement!
Why? Let's take a look.
Cut Current Line
Like it says, this command cuts whatever line the cursor is on (meaning it copies it and deletes the line, including the carriage return). You can use this to easily move a line up or down, or to just delete a line. There is a command that deletes the line without cutting it (Shift+Del), but when you're just starting out it pays to limit the number of things you're learning all at once. Ctrl+L does the same thing that Shift+Del does, and rarely will the difference ever bite you. Start simple.
"Cool man, but like, why is this such an efficiency improving short cut?"
Glad you asked! Here's the sequence of keys I used to hit to do the same thing Ctrl+L does in one keystroke:
If you edit at all like I used to, these 3 shortcut keys will save you a huge number of redundant keystrokes every single day. Yep, just learning 3 new shortcut keys.
I'm not going to keep you waiting, here they are:
| Shortcut | Action |
|---|---|
| Ctrl+L | Cut current line |
| Ctrl+C (with NOTHING selected) | Copy current line |
| Ctrl+Enter | Insert blank line above |
I have learned tons of new shortcut keys since I started this process, but these three are the most important. If you learn this and nothing else in this series, it will still be a marked improvement!
Why? Let's take a look.
Cut Current Line
Like it says, this command cuts whatever line the cursor is on (meaning it copies it and deletes the line, including the carriage return). You can use this to easily move a line up or down, or to just delete a line. There is a command that deletes the line without cutting it (Shift+Del), but when you're just starting out it pays to limit the number of things you're learning all at once. Ctrl+L does the same thing that Shift+Del does, and rarely will the difference ever bite you. Start simple.
"Cool man, but like, why is this such an efficiency improving short cut?"
Glad you asked! Here's the sequence of keys I used to hit to do the same thing Ctrl+L does in one keystroke:
- End
- Shift+Up
- Ctrl+X
3 keystrokes when I could have used 1! Suppose you delete or move lines 100 times a day, which is probably crazy low. You would save 200 keystrokes. This paragraph is only 195 characters long.
Maybe that doesn't seem like a lot, but there is a hidden benefit here too; Ctrl+L is a single command that maps directly to a pretty high level action you wanted to take. It may be only 2 keystrokes better than the more manual way, but you don't have to busy yourself thinking about the micro steps required to move the cursor and highlight text. You just, BAM, do the action you want. End. Of. Story. Conceptual overhead here is much reduced!
Copy Current Line
I used to do this the same as above, except I'd Ctrl+C instead of Ctrl+X. But it turns out, if you just hit Ctrl+C when nothing is selected, VS will copy the entire line! Brilliant!
Suppose I copy half as many lines as I delete: 50/day =100 keys saved. This paragraph is 98 chars.
Add Blank Line Above
You might not think that you do this operation too often, but I think you'll be surprised. How many times do you write a block surrounded by {}? There are LOTS of ways you might do this, but the way I usually do it is I write the definition, the open {, and then the closing }, and now I want to go back up and type in the body, but I'm stuck below it!
Here's what I do:
- Up
- End
- Enter
That's 3 keystrokes again instead of just Ctrl+Enter! Interestingly, this is the one I'm having the hardest time training myself to take advantage of. That could be because how often I use it varies depending on what I'm coding, but I bet on a typical day I do this way more than I copy lines. Lets go with 200 times a day, for 400 keys saved. And you guessed it, this paragraph is 396 chars.
So with all three of these combined, and given my completely made up numbers, that's 700 keystrokes saved, every day, just by using these three shortcut keys, That's clearly a good thing, but the real benefit is in the fact that you're now communicating with your editor on a higher level than just cursor up and down.
Monday, October 14, 2013
Embracing The Beast: Navigate To
Next up in the Embracing The Beast series is Navigate To.
The Navigate To feature introduced in Visual Studio 2010 is the single most important feature they added that made it possible for me to work in Visual Studio without proclaiming my longing and desire for Vim at the top of my lungs every 5 minutes.
The shortcut is Ctrl+, (Control Comma). But the shortcut is just the beginning of effectively using this thing.

What it searches
Files, types, members, and variables.
Search string formats
An all lower case search basically does a case-insensitive "contains" search, but it intelligently sorts the results preferring "Starts With" over "Contains". For example, if you search for "ext", you'll find things like Properties named "Extension" or Methods named "Extract" before you'll find Properties named "Text".
But change your search string so that's it's not all lower case, "Ext", and now it does a case sensitive search which would still return "Extension" and "Extract" but not "Text".
Make your search string all upper case, and now it does a PascalCaseAware search! For example, search for "AVE" and it will match AbstractValidatorExtensions because of the PascalCase, and "AutoSave" because of the case insensitive contains match of "ave" in "Save". Unfortunately it returns the contains matches before the pascal case matches, so this can require a lot of pascal case characters before it will return the item you want at the top.
Put spaces between search terms and it basically does an "and" search, but it's position independent. "auto save" will of course match "AutoSave", but so will "save auto"! Lest I mislead you, the matches don't have to be adjacent, "location incident" will match "AddLocationToSomeIncident".
Tips
Suppose you are looking for a file, and you know part of its name and you know its a JavaScript file. Search for "partofname .js". The ".js" will bring .js files to the top of the results.
Suppose you're looking for the Index view of an MVC controller. There are lots of Index views in your website I bet, so searching for just "index" isn't going to get you too far. Try this: "views partofcontrollername index". partofcontrollername just has to be a unique enough subset of the name of the controller to bring that folder to the top. This illustrates that Navigate To isn't just searching the file name, but the entire file path!
If you have more Navigate To tips, I want to hear them! Comment below or twitter at me!
The Navigate To feature introduced in Visual Studio 2010 is the single most important feature they added that made it possible for me to work in Visual Studio without proclaiming my longing and desire for Vim at the top of my lungs every 5 minutes.
The shortcut is Ctrl+, (Control Comma). But the shortcut is just the beginning of effectively using this thing.
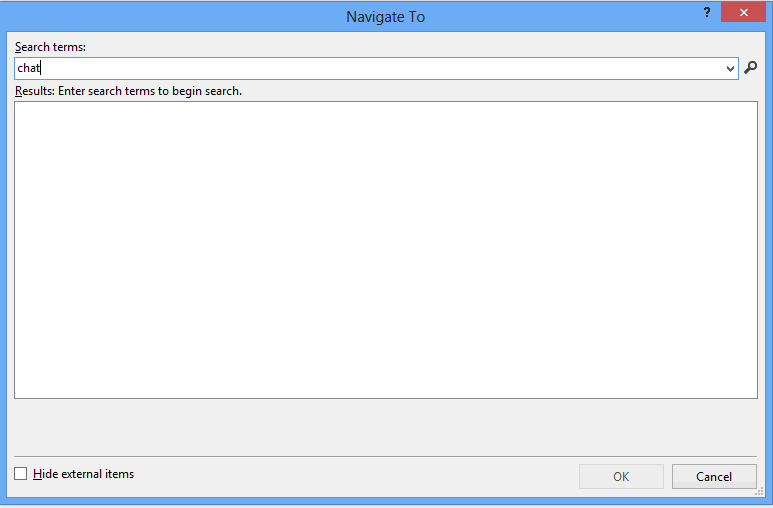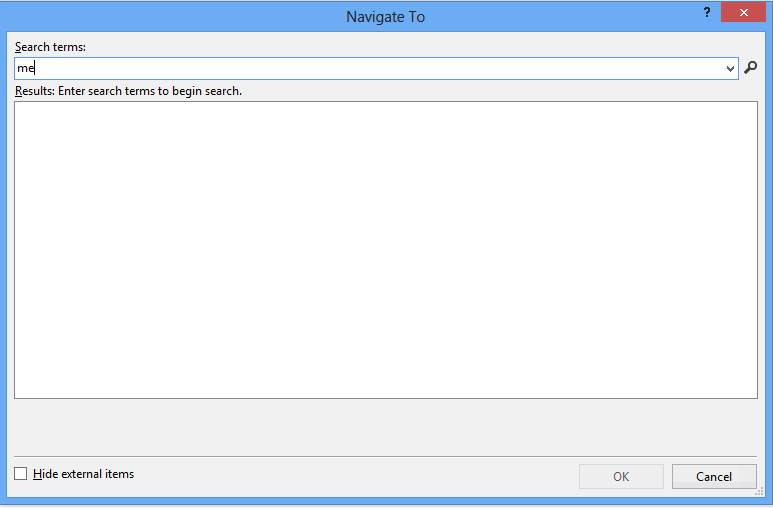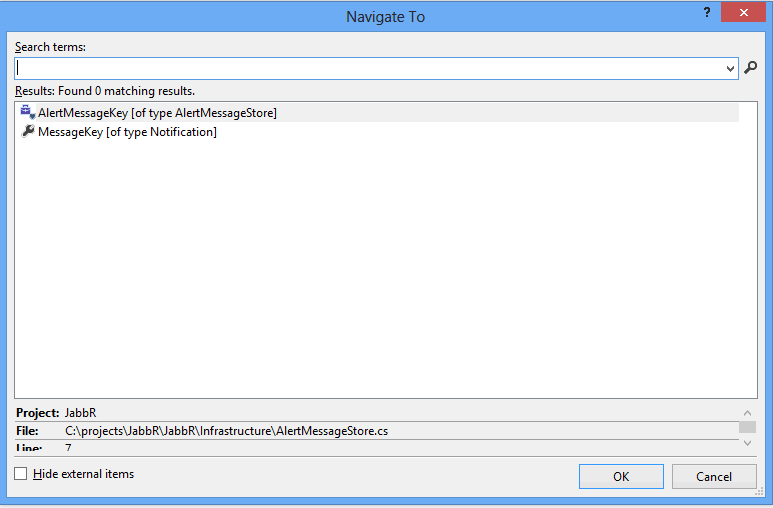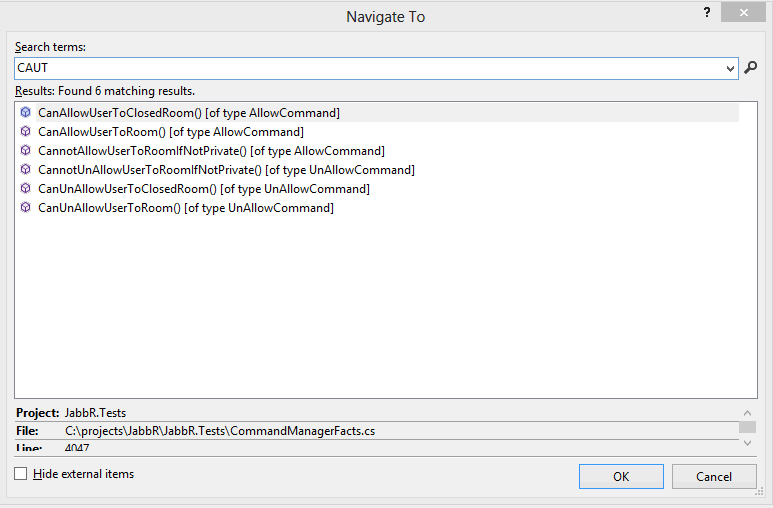
What it searches
Files, types, members, and variables.
Search string formats
An all lower case search basically does a case-insensitive "contains" search, but it intelligently sorts the results preferring "Starts With" over "Contains". For example, if you search for "ext", you'll find things like Properties named "Extension" or Methods named "Extract" before you'll find Properties named "Text".
But change your search string so that's it's not all lower case, "Ext", and now it does a case sensitive search which would still return "Extension" and "Extract" but not "Text".
Make your search string all upper case, and now it does a PascalCaseAware search! For example, search for "AVE" and it will match AbstractValidatorExtensions because of the PascalCase, and "AutoSave" because of the case insensitive contains match of "ave" in "Save". Unfortunately it returns the contains matches before the pascal case matches, so this can require a lot of pascal case characters before it will return the item you want at the top.
Put spaces between search terms and it basically does an "and" search, but it's position independent. "auto save" will of course match "AutoSave", but so will "save auto"! Lest I mislead you, the matches don't have to be adjacent, "location incident" will match "AddLocationToSomeIncident".
Tips
Suppose you are looking for a file, and you know part of its name and you know its a JavaScript file. Search for "partofname .js". The ".js" will bring .js files to the top of the results.
Suppose you're looking for the Index view of an MVC controller. There are lots of Index views in your website I bet, so searching for just "index" isn't going to get you too far. Try this: "views partofcontrollername index". partofcontrollername just has to be a unique enough subset of the name of the controller to bring that folder to the top. This illustrates that Navigate To isn't just searching the file name, but the entire file path!
If you have more Navigate To tips, I want to hear them! Comment below or twitter at me!
Tuesday, October 8, 2013
Embracing The Beast: Where Do We Start?
The Beast, as explained in the first post, is Visual Studio, and my objective is to finally really master it once and for all. What's the criteria for "master"? It's not a simple question because VS has so many different parts and features... Does mastering it mean you know when and how to use every single one of those features? Does mastering it mean you use it as fast and efficiently as possible? Where's a poor vim-loving-wanna-be-hippie-alt-dot-net-developer to start?
There's two main related places I believe make the most sense to start, and that I believe will help drive out learning what other bells and whistles and sirens and synthesizers VS has to offer:
There's two main related places I believe make the most sense to start, and that I believe will help drive out learning what other bells and whistles and sirens and synthesizers VS has to offer:
- Let go of the mouse
- Touch fewer keys
That's it. Just those two things should give us a really solid start at becoming much faster and more efficient when coding in VS.
I'm guessing I don't really have to convince most of the people reading this that this is correct. But, you know, it's low hanging fruit, so I'm going for it anyway... Maybe you like the mouse. Maybe you read that one ancient article from the early Mac days that says using the mouse is actually more efficient than the keyboard. OK. Tell me, how often do you save the file you are editing by:
- Grabing the mouse
- Dragging waaaaaaaaaaaaaaaaaaaaaaay over (monitors are BIG these days) to the File menu, clicking it
- Dragging down to the save item, clicking it
Or do you just hit Ctrl+S like 100,000 times subconsciously every time you stop to think about what to do next?
I thought so.
That's the thing about keyboard shortcuts, once you have practiced them to the point where they are engrained in your muscle memory, they are fast and require no thought and no time lag, allowing you to forget the physical steps of editing and focus on the more abstract ideas of what you are editing. But lets not skim over the most important part of that last sentence: practice! Real practice. The kind of practice familiar to most people who have played a musical instrument of some kind, which mainly consists of repetition, repetition, repeating yourself, doing it again, and again, repetition, slow repetition, fast repetition, and then more repetition. And if you didn't study music but instead spent your time going to sporting rehearsals (is that what they're called?), you probably experienced much the same thing.
So, if we are going to let go of the mouse, and touch fewer keys, we're going to have to practice shortcut keys. For me that practice usually looks like:
- Learning a new shortcut key
- Writing it down
- Trying it out a few times
- Purposefully finding opportunities to use it
- Paying close attention to my coding and if I miss a chance to use it,
- leaning on undo
- doing it again with the shortcut
Repeat, repeat, repeat, repeat, repeat. It's also important not to stretch yourself too thin all at once. Focus on a couple things at a time, work 'em to death, then do some other things, then go back to the first things again, etc. Some of this is going to be extra-curricular. Some of it can happen on the job. Some of it will slow you down a bit. It's OK, you're going to be happier for it soon. And it's not going to take as long as it feels like it does. I have no studies to prove this, I believe it on blind faith alone, and encourage you to take my word for it. We're software developers after all and that's how we do this.
OK, cool. So we need some shortcut keys to learn.
The Basics
These are the essentials, chances are anyone who's used VS for any amount of time knows these already, so let's get them out of the way.
| Shortcut | Action |
|---|---|
| F6 or Ctrl+Shift+B | Build |
| Ctrl+F4 | Close Window |
| Ctrl+, | Navigate to |
| F5 | Run |
| F9 | Toggle Breakpoint |
| F10 | Debugger Step Over |
| F11 | Debugger Step Into |
| Ctrl+R, T | Run Tests |
| These you already know | cut, copy, paste, undo, redo, save |
Slightly Better Than Basic
Moving a tiny bit up the scale toward shortcuts that are still bread and butter, but might be slightly less well known.
| Shortcut | Action |
|---|---|
| Shift+F5 | Stop Debugging |
| Ctrl+E, C | Comment Selection |
| Ctrl+E, U | Uncomment Selection |
| Ctrl+M, M | Toggle Outlining |
| Ctrl+M, L | Toggle All Outlining |
| Ctrl+G | Go to Line |
| Shift+F6 | Build Current Project Only |
Learning shortcut keys isn't all there is to mastering an editor, but it's a big part, and it's certainly the first step. With these basics out of the way, we can move on to more interesting stuff.
Friday, October 4, 2013
Embracing The Beast

Like your first language, your first editor molds your expectations. Brief was a keyboard driven, light weight, text focused editor. It was brief. And it had really really good (and brief) help. I no longer remember any of it's shortcut keys or even much about it's interface, but I still remember spending hours navigating through it's help like it was Wikipedia, "oh that sounds interesting." *click* "huh, what's that?" *click* "oooh! that sounds cool!" *click*.
But I was working and schooling in the land of the beast now, so no more Brief. And compared to Brief, Visual Studio is a BEAST! Slow, mouse oriented, cluttered with tool windows sliding in and out from every direction, toolbars everywhere with countless incomprehensible icons. And no help.
I think I did C++ in VS for a full year before I learned about the debugger, arguably VS's killer feature. Isn't the whole point of all this UI mouse driven stuff to make it more discoverable? It didn't work for me. It wasn't my expectation from my Brief days and with the really bad help, I had no way to learn it on my own. I finally learned it from one of my classmates, watching over their shoulder as they tried to fix a bug. My life changed that day: no more print statement debugging!
I learned a lot of Visual Studio after that, but I never liked it, and I never found a good resource to help me learn more about it. I didn't feel bad about it, cause VS was still a slow, ugly, bloated beast. And, I seriously hated it so much I invested ALOT of time configuring Vim to do C# development completely outside of VS.
But that began to change about 3 years ago with VS 2010. It got faster and more usable in some key ways (though slower in others), and suddenly I found myself spending less time in Vim and more time in VS. It also helped that I was doing more web development than winforms or wpf development. Then with VS 2012, it got dramatically better still. I installed VsVim and hardly switched into Vim at all anymore.
It took awhile before I realized I really didn't hate Visual Studio anymore. And awhile longer after that before I realized, "Hey, I bet if I studied this thing the way I studied Vim back in the day, I could wring a lot of performance out of it". So I started paying attention to how I was using it, and I started researching VS tips, VS shortcuts, VS productivity. I haven't found one single good resource, but there's plenty of random blogs with scattered tips.
Then this week, I took a big step. I turned off VsVim. **gasp!**
So far, it's been a surprisingly good experience. Better than I was hoping. I'd like to write up some of what I'm learning here, much like the Vim series. But I'm still working on ideas of how to present it. It's harder than with Vim, VS being such a beast and all...
Wednesday, August 7, 2013
Powershell: Open Files Matching a Search
Have I ever mentioned how much I love Powershell?
What do you do when you want to search a bunch of source files for a given string, and then open all the files that matched your search?
First you have to be able to search a bunch of files, my earlier post Powershell Grep has you covered there. This outputs objects (a MatchInfo if you want to know) that list the files and lines that matched. If a file had multiple matching lines, it will be listed twice, so we need to do something about that. Then we'll need to assemble all the file paths and pass it into our favorite editor (Vim, no surprise there).
In Powershell V3 syntax the command is:
If you develop on the Windows platform and you haven't given Powershell a look yet, you really really should. I learned it by reading Windows Powershell In Action, a book I really enjoyed for its brevity, good examples, and awesome asides about how and why certain design decisions were made in the language.
What do you do when you want to search a bunch of source files for a given string, and then open all the files that matched your search?
First you have to be able to search a bunch of files, my earlier post Powershell Grep has you covered there. This outputs objects (a MatchInfo if you want to know) that list the files and lines that matched. If a file had multiple matching lines, it will be listed twice, so we need to do something about that. Then we'll need to assemble all the file paths and pass it into our favorite editor (Vim, no surprise there).
In Powershell V3 syntax the command is:
gvim (grep SearchString | group-object Path).NameIn Powershell V2 syntax you have to use ForEach-Object:
gvim (grep SearchString | group-object Path | %{ $_.Name })
If you're a programmer, especially if you're a .NET programmer, powershell is just so wonderfully intuitive (even if it is a bit verbose)!If you develop on the Windows platform and you haven't given Powershell a look yet, you really really should. I learned it by reading Windows Powershell In Action, a book I really enjoyed for its brevity, good examples, and awesome asides about how and why certain design decisions were made in the language.
Tuesday, June 4, 2013
Powershell: testing string length validations
Every time I do this it makes me smile.
If you write apps that have input fields that have max lengths that are validated, then occasionally you may need to test your validations. I used to do this by typing "this is a really really really long string that should break the validations" and the copying and pasting that over and over until I thought I'd gotten it long enough to exceed the max length.
Now I just switch over to powershell (which I always have conveniently open and ready) and I type:
"quite long" just happens to be exactly 10 characters long, so this generates a string which is 1000 characters long that looks like "quite longquite longquite long..." Piping that string to clip.exe saves it on your clipboard. Now just paste into the field you want to test and you're all set!
If you write apps that have input fields that have max lengths that are validated, then occasionally you may need to test your validations. I used to do this by typing "this is a really really really long string that should break the validations" and the copying and pasting that over and over until I thought I'd gotten it long enough to exceed the max length.
Now I just switch over to powershell (which I always have conveniently open and ready) and I type:
"quite long" * 100 | clip.exe
"quite long" just happens to be exactly 10 characters long, so this generates a string which is 1000 characters long that looks like "quite longquite longquite long..." Piping that string to clip.exe saves it on your clipboard. Now just paste into the field you want to test and you're all set!
Saturday, April 13, 2013
Insight in Plastic Containers

Two simple small plastic containers. The one on the left is a considerably better design:
- They nest inside each other because of the tapered shape
- The base of the container snaps into the top of the lid
- The lids snap into each other
I love examples of good design like this, but that's not why I took this picture!
On the one on the left, see how the lid is facing down and the container fits on top of it, like this?

We have way more left-type containers and only a couple right-types. The right-types don't fit into each other, and the lids don't snap on the bottom, so there isn't any great way to store them. I usually just stuff 'em in the cabinet. But today I opened the cabinet door and noticed the lid on the right-type as in the photo:
.png)
FLIPPED! It's facing up instead of down, and the container nests relatively nicely inside it. I couldn't help but smile at this!
I have been fixated on the lids facing down because we have many more of the left-type containers, the idea of simply flipping the lid never occurred to me. It's wonderful to reflect on the insight of just flipping the lid around. A terribly simple idea that has been there all along, but I never saw it.
An admittedly silly example of lateral thinking... Or maybe it's not really lateral thinking, maybe it's just closed mindedness through familiarity. But in any case, when I saw it today it made me go "neat!"
Monday, February 11, 2013
POODR's Duck Types
 I recently read Practical Object-Oriented Design in Ruby by Sandi Metz. It's a really wonderful book. I can say without any hesitation it has made me a much better Object-Oriented programmer. I honestly wish I could have read this 12 years ago when I was first learning an Object-Oriented language.
I recently read Practical Object-Oriented Design in Ruby by Sandi Metz. It's a really wonderful book. I can say without any hesitation it has made me a much better Object-Oriented programmer. I honestly wish I could have read this 12 years ago when I was first learning an Object-Oriented language. Although the book is totally focused on Ruby, the OO practices it presents are easily applicable to other OO languages, including static languages like C#. This makes it one of those timeless books you can be happy to have on your shelf knowing it's not going to be outdated in a year. I highly recommend it!
I intend to write a few posts highlighting some of the good ideas that struck me the most from this book, but in this post I just can't help but take a few shots at it's treatment of static vs. dynamic languages.
My programming language lineage started by dabbling in C, then taking classes in C++, followed by Java, and finally C#. Most of the real world code I've written has been in static languages, and I've been programming professionally in C# for the last 8 years. This makes me a static language guy.
When I learned ruby, about 5 years ago, I fell in love with it's clean syntax and amazing flexibility. I wrote a few simple tools in it for work, and I've written alot of rspec/capybara tests, plus I dabbled a bit with Rails. I feel I have a decent understanding of the language, but I'm by no means an expert and I definitely still think in classes and types.
I tell you this to explain where I'm coming from. Static languages are what I know best and are what I'm used to. I'm not a dynamic language hater, I'm just comfortable with static langs. Which brings us back to POODR.
POODR talks a lot of about "Duck Types" which are defined in the book as:
Duck types are public interfaces that are not tied to any specific class. These across-class interfaces add enormous flexibility to your application by replacing costly dependencies on class with more forgiving dependencies on messages.I was surprised at this definition because it describes the "Duck type" as being a thing, but in Ruby there is no thing that can represent this across-class-interface. Most treatments of duck typing from Rubyists I've seen usually just talk about how it's a feature of the dynamic nature of the language. They talk about "duck typing" but not "duck types."
In C# we have interfaces, which can be used as explicitly defined duck types. The Dependency Inversion Principle and the Interface Segregation Principle are both trying to get you to use interfaces in this way, instead of just as Header Interfaces. It's good OO because it focuses on messages instead of types. As POODR says, "It's not what an object is that matters, it's what it does."
I think there is a lot of power in Ruby's implicit "duck types," but I also think the lack of explicit interfaces is a serious liability, and I was very entertained by how many hoops POODR jumps through to try to work around this problem, all while trying to claim that it isn't a problem at all, and in fact, it's great!
At the end of Chapter 5, there's a section that tries to convince you that Dynamic typing is better than Static typing. Unfortunately, it just builds up a straw man version of static typing to make it easier to tear down. What it leaves out is interfaces:
Duck typing provides a way out of this trap. It removes the dependencies on class and thus avoids the subsequent type failures. It reveals stable abstractions on which your code can safely depend.If statics langs didn't have interfaces, this might be true. But they do have interfaces! And worse, interfaces represent a significantly more stable abstraction that is dramatically safter to depend on than these invisible "duck types." POODR demonstrates this itself with examples where the "duck type" interface changes, but not all "implementers" of the interface are updated. There's no compiler to catch this. And standard TDD practices wont catch it either. Your tests will be green even though the system doesn't work. So you have to write manual tests that you can share across all the implementers to make sure the message names and parameters stay in sync. Nearly all of Chapter 9 is devoted to testing practices that simply wouldn't be needed if there was even just a rudimentary compiler that could verify just inheritance and interface implementations.
The lack of explicit "duck types" just seems so problematic to me... Keeping them in sync is a chore, and a potential source of error. The worst kind of error too, because the same code may work in one context but break in another based on which "duck type" is used.
Another problem I've run into is when trying to understand some code that takes in a "duck type", how do you figure out the full story of what will happen? How do you find all the implementers of that "duck type"? Just search your code base for one of the method names? Try to find every line of code that injects in a different duck type?
Not being able to surface an explicit interface leaves you stuck in a situation where you have to infer the relationship between your objects by finding every usage of them. Seems like a lot more work, as well as being a recipe for tangled and confusing code.
So what do you think Dynamic language people? Am I making a bigger deal out of the problems of dynamic typing just as Sandi made a bigger deal out of the problems of static typing? Is this just a lack of experience problem? Do you just not run into these issues that often in real world usage?
UPDATE 2/20/2013:
Here's an interesting presentation by Michael Feathers about the power of thinking about types during design. I felt like it had some relevance to the conversation here.
Monday, February 4, 2013
In The Midst of Wonders
"Where the uninformed and unenquiring eye perceives neither novelty nor beauty, he walks in the midst of wonders" - John Hershel, from The Age of Wonder, originally from A Preliminary Discourse on the Stud of Natural Philosophy
Tuesday, January 29, 2013
Custom and Example
"I thus concluded that it is much more custom and example that persuade us than any certain knowledge, and yet inspite of this the voice of the majority does not afford a proof of any value in truths a little difficult to discover, because such truths are much more likely to have been discovered by one man than by a nation." - Rene Descartes, Discourse on Method and Meditations
Thursday, January 24, 2013
The Basics
Some body I follow on twitter retweeted this tweet from Tim Ottinger:
I remember programming like that. There was a time, not long ago, when I didn't think I should extract a method unless I meant to use it more than once! And it's weird because I don't remember having the epiphany that took me from where I was then to where I am now. I once thought A, I now think B, and I don't remember changing my mind. It's an interesting lesson in the way the mind works. And it reminded me that everyone was a newbie once, and that most likely, I still am a newbie I just haven't figured it out yet.
The reason for writing a function is not to reuse its code, but to name the operation it performs.My first pompous thought was something like, "how obvious." I was about to go back to work when a memory hit me out of no where. I remember very early in my career F5-hacking on some code and thinking about creating a method but worrying about not reusing it, or about someone else reusing it incorrectly, or about the extra lines of code the added syntax would add to my already 1000+ line Windows Form class.
— Tim Ottinger (@tottinge) January 22, 2013
I remember programming like that. There was a time, not long ago, when I didn't think I should extract a method unless I meant to use it more than once! And it's weird because I don't remember having the epiphany that took me from where I was then to where I am now. I once thought A, I now think B, and I don't remember changing my mind. It's an interesting lesson in the way the mind works. And it reminded me that everyone was a newbie once, and that most likely, I still am a newbie I just haven't figured it out yet.
Friday, December 21, 2012
Slicing Concerns: Implementations
In Slicing Concerns And Naming Them I posed a question about how to go about separating different concerns while still maintaining a clean and relatable code base. Some interesting conversation resulted, and I wanted to follow up by investigating some of the different approaches to this problem that I'm aware of.
Inheritance
Decorator
The naming is a bit suspect, because NotificationTask is not really a task, it just has a task. It implements only one of the task's methods. If we extracted an ITask interface we could make NotificationTask implement it and just forward all the calls. This would make it a task (and a decorator), but would also be crazy tedious.
Service
The naming is pretty nice here, hard to be confused about what CreatesTask does... However, this path leads to a proliferation of <verb><noun> classes. In the small it's manageable, but as they accumulate, or as they start to call each other things get confusing. For example, if you know nothing about Task and you have to start working on it, would you know you should call the CreatesTask service? Would you know it exists? And would you be sure it was the correct service for you to be calling?
Dependency Injection
The idea here is to pass in an INotifier, and then when you find yourself dealing with a task you'll build it with the notifier you want it to use. If you want no notification, you use the Null Object pattern and pass in an INotifier that doesn't do anything (called NullNotifier in the code example).
Operational vs Data Classes
If I missed anything, or if you see an important variation I didn't think of, please tell me about it! As always you can talk to me on twitter, and you can still fork the original gist.
Inheritance
public class Task : ActiveRecord
{
public string Name { get; set; }
public int AssignedTo_UserId { get; set; }
public DateTime DueOn { get; set; }
}
public class NotificationTask : Task
{
public override void Save()
{
bool isNew = IsNewRecord;
base.Save();
if (isNew)
Email.Send(...);
}
}
public class TasksController : Controller
{
public ActionResult Create(...)
{
...
new NotificationTask {...}.Save();
...
}
public ActionResult CreateWithNoEmail(...)
{
...
new Task {...}.Save();
...
}
}
This works, and the names are reasonable. But of course, inheritance can cause problems... I wont go into the composition over inheritance arguments as I assume this isn't the first time you've heard it!Decorator
public class Task : ActiveRecord
{
public string Name { get; set; }
public int AssignedTo_UserId { get; set; }
public DateTime DueOn { get; set; }
}
public class NotificationTask
{
Task task;
public NotificationTask(Task t)
{
this.task = t;
}
public void Save()
{
bool isNew = t.IsNewRecord;
t.Save();
if (isNew)
Email.Send(...);
}
}
public class TasksController : Controller
{
public ActionResult CreateTask()
{
...
new NotificationTask(new Task {...}).Save();
...
}
}
This is not really the decorator pattern... At least not as defined by the GoF, but I have seen it used this way often enough that I don't feed too terrible calling it that. Really this is just a wrapper class. It's similar to the inheritance approach, except because it doesn't use inheritance, it opens us up to use inheritance on the Task for other reasons, and apply the email behavior to any kind of task.The naming is a bit suspect, because NotificationTask is not really a task, it just has a task. It implements only one of the task's methods. If we extracted an ITask interface we could make NotificationTask implement it and just forward all the calls. This would make it a task (and a decorator), but would also be crazy tedious.
Service
public class Task : ActiveRecord
{
public string Name { get; set; }
public int AssignedTo_UserId { get; set; }
public DateTime DueOn { get; set; }
}
public class CreatesTask
{
Task task;
public NotificationTask(Task t)
{
this.task = t;
}
public void Create()
{
t.Save();
Email.Send(...);
}
}
This service represents the standard domain behavior for creating a task. In an edge case where you needed a task but didn't want the email, you would just not use the service.The naming is pretty nice here, hard to be confused about what CreatesTask does... However, this path leads to a proliferation of <verb><noun> classes. In the small it's manageable, but as they accumulate, or as they start to call each other things get confusing. For example, if you know nothing about Task and you have to start working on it, would you know you should call the CreatesTask service? Would you know it exists? And would you be sure it was the correct service for you to be calling?
Dependency Injection
public class Task : ActiveRecord
{
public string Name { get; set; }
public int AssignedTo_UserId { get; set; }
public DateTime DueOn { get; set; }
INotifier notifier;
public Task(INotifier notifier)
{
this.notifier = notifier;
}
public override void Save()
{
bool isNew = t.IsNewRecord;
t.Save();
if (isNew)
notifier.Send(...);
}
}
public class TasksController : Controller
{
public ActionResult Create(...)
{
...
new Task(new EmailNotifier()) { ... }.Save();
...
}
public ActionResult CreateWithNoEmail(...)
{
...
new Task(new NullNotifier()) { ... }.Save();
...
}
}
I'm going to ignore all the complexity around the fact that this is an ActiveRecord object which the ActiveRecord framework will usually be responsible for new-ing up, which makes providing DI dependencies difficult if not impossible...The idea here is to pass in an INotifier, and then when you find yourself dealing with a task you'll build it with the notifier you want it to use. If you want no notification, you use the Null Object pattern and pass in an INotifier that doesn't do anything (called NullNotifier in the code example).
But this has the ORM-framework draw back I mentioned above. Plus it requires the code that is constructing the task to know what behavior the code that is going to save the task will require. Most of the time that's probably the same code, but if they aren't, you're out of luck.
Operational vs Data Classes
public class TaskInfo
{
public string Name { get; set; }
public int AssignedTo_UserId { get; set; }
public DateTime DueOn { get; set; }
}
public class TaskList
{
public TaskInfo Create(TaskInfo t)
{
t.Save();
notifier.Send(...);
return t;
}
}
Here I've separated the data class from the operational class. I talked about this in the Stratified Design series of posts. This separation hides ActiveRecord, giving us the control to define all of our operations independently of the database operations they may require. If we needed to save a task without sending an email we could just call TaskInfo.Save() directly from whatever mythical operation had that requirement. Or we could do some extract method refactorings on the Task.Create method to expose methods with just the behavior we need. Or we might extract another class. Naming is going to be hard for these refactorings, but at least we have options.If I missed anything, or if you see an important variation I didn't think of, please tell me about it! As always you can talk to me on twitter, and you can still fork the original gist.
Subscribe to:
Posts (Atom)